记一次在压力测试期间出现的问题:
对服务器上部署的项目进行压力测试期间出现的一些问题的描述和解决方案。
- 被测试的服务器配置:8核16G。已经按照git上的服务器部署文档进行了内核参数的修改,提高服务器的性能,主要涉及最大进程数,TCP连接数的配置。截取部分如下。
# /etc/sysctl.conf
fs.file-max = 10000000
fs.nr_open = 10000000
net.ipv4.tcp_mem = 786432 1697152 1945728
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
et.ipv4.netfilter.ip_conntrack_max = 655350
# /etc/security/limits.conf
root soft nofile 1000000
root hard nofile 1000000
* soft nofile 1000000
* hard nofile 1000000
- 被测内容:使用预先生成的缓存来作为接口的数据响应。
问题1:使用缓存也无法有效提高吞吐量
问题描述:
将所有的数据来源从预先生成的Redis缓存中获取,涉及的操作为纯字符串操作,不涉及复杂的耗时数学计算,服务器性能应该会有较大的提升。实际压力测试时,当线程组处于一个适中的水平的时候,吞吐量较低,和在内网Demo版本的压力测试差距较大,且Demo版本的服务器性能相比被测服务器配置更低。
问题解决:
项目基于Vert.x框架进行开发,通过对比Demo版本的接口和正式对外接口的代码发现,demo接口使用handler()方法来处理路由请求,正式接口使用blockingHandler()处理路由请求。根据查询文档和博客资料得到:
blockingHandler()方法来设置阻塞式处理器,会使用 Worker Pool 中的线程而不是 Event Loop 线程来处理请求。例如:
router.route().blockingHandler(routingContext -> {
// 执行某些同步的耗时操作
service.doSomethingThatBlocks();
// 调用下一个处理器
routingContext.next();
});
默认情况下在一个 Context(Vert.x Core 的
Context,例如同一个 Verticle 实例) 上执行的所有阻塞式处理器的执行是顺序的,也就意味着只有一个处理器执行完了才会继续执行下一个。 如果您不关心执行的顺序,并且不介意阻塞式处理器以并行的方式执行,您可以在调用blockingHandler()方法时将ordered设置为 false。
最终将路由处理方法 blockingHandler()的ordered 参数设置为 false,重新进行压力测试,恢复到了预期的水平。
参考文档:
https://vertxchina.github.io/vertx-translation-chinese/web/Web.html ,”使用阻塞式处理器“部分。
https://leokongwq.github.io/2017/11/21/vertx-web-route.html
https://colobu.com/2016/03/31/vertx-thread-model/
问题2:提高线程组出现较高的错误率
注:本机无法支持较高的线程组进行测试,将Jmeter环境部署到跨机房的服务器上,使用该服务器对目标服务器进行测试。
问题描述:
将线程组的值提高明显的一个数量级,开始出现一定的错误率,查看被测服务器项目的日志后,并没发现有异常信息打印,全部为从缓存中取得数据。接着查看Jmeter的日志,出现了异常内容,内容如下:
Non HTTP response code: java.net.NoRouteToHostException,Non HTTP response message: Cannot assign requested address (Address not available)
分析为目标服务器无法连接,导致超时出现错误。查询资料得:
由于liunx 分配的客户端连接端口用尽,无法建立socket连接所致,虽然socket正常关闭,但是端口不是立即释放,而是处于 TIME_WAIT 状态,默认等待60s后释放。
即已经处理过的TCP连接并未立即释放socket句柄,导致后续连接无法处理,出现错误日志。
执行 cat /proc/sys/net/ipv4/ip_local_port_range查看liunx支持的客户端连接端口范围,也就是 28232 个端口。
解决方法:
-
调低端口释放后的等待时间,默认为60s,修改为15~30s。
echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout -
修改 TCP/IP 协议配置,通过配置
/proc/sys/net/ipv4/tcp_tw_reuse,默认为0,修改为1,释放TIME_WAIT端口给新连接使用。echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse -
修改 TCP/IP 协议配置,快速回收socket资源,默认为0,修改为1。
echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
# /bin/bash
echo 20 > /proc/sys/net/ipv4/tcp_fin_timeout
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
参考文档:
https://my.oschina.net/shichangcheng/blog/1560864
问题3:继问题2后提高线程组,延迟较高
问题描述:
按照问题2 中的解决方法调整被测服务器的参数配置,吞吐量提升明显,但是还出现了少量的错误率,且部分延迟较高,查询日志和问题2中的异常内容一致。
解决方法:
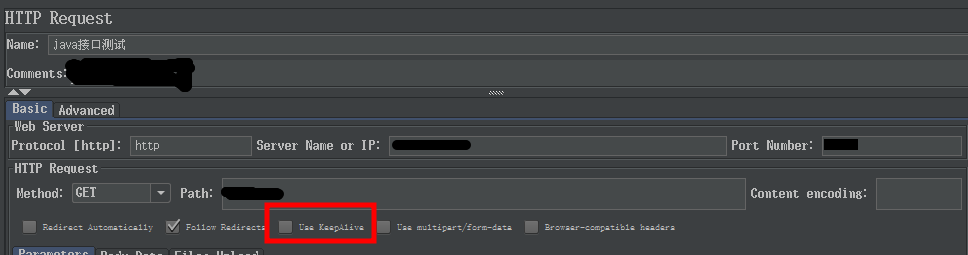
仔细看了一下官方说明发现这几个参数都是对长连接进行的优化,马上想到Jmeter是否有"keep alive"选项。取消勾选后果然一切正常
如图所示,在Jmeter的HTTP Request中,取消Use Keep Alive选项,重新进行测试,就没有出现错误了。
参考文档:
https://www.jianshu.com/p/ceced42cb8bb
补充问题4:修改Jmeter最大内存,同配置出现错误
问题描述:
将Jmeter启动脚本中的最大可用内存-Xmx1g修改为-Xmx4g,按照前期相同的过高的并发请求下出现了错误率。查看日志同样还是该异常。
Non HTTP response code: java.net.NoRouteToHostException,Non HTTP response message: Cannot assign requested address (Address not available)
此时服务器配置已经按照之前的解决方法调整过,在未修改前已经达到了0错误率,但是在修改Jmeter的最大内存数后又出现了错误。当改回-Xmx1g后,恢复先前0错误率的正常水平。
分析原因:
先前出现该原因是由于被压测服务器的TCP连接释放问题导致新的请求无法建立连接,从而出现问题,此时错误是出现在被测试方服务器。
当修改Jmeter的最大内存数后又出现该原因分析是在请求方服务器在执行压力测试时,由于可用最大内存变大可创建同时更多的TCP连接请求,但是由于本机限制又无法建立连接从而出现错误,此时错误是出现在请求方服务器。
可能的解决方案(未测试验证):
net.ipv4.ip_local_port_range参数规划出一段端口段预留作为服务的端口,通常客户端端口都是随机分配的,这个参数就是指定这个随机的范围。
查看本机的可用端口数,,当前为:
root@debian:/usr/cert_server# sysctl -a | grep range
net.ipv4.ip_local_port_range = 32768 61000
net.ipv4.ping_group_range = 1 0
调整该参数范围,可以提高Jmeter的并发请求数量。
结论:
在不了解修改配置可能产生的影响时,不要轻易修改默认配置。